Vorlesung 9. November 2015 #
01 - RDF Reification #
Reifikation erlaubt es in RDF, Aussagen über Aussagen zu treffen. Dazu hilft rdf:Statement, das seinerseits rdf:subject, rdf:predicate und rdf:object enthält. Reifikation kann dazu verwendet werden, um
- die Herkunft von Daten auszudrücken,
- Aussagen über Verlässlichkeit und Glauben zu treffen (bspw. glaubt, dass; meint, dass) oder
- Metadaten über Aussagen zu machen
02 - Model Building with RDFS #
RDFS; RDF Vocabulary Description Language
RDFS macht es u.a. möglich,
- Definitionen von Klassen via
rdfs:Classund (Bsp.: :Planet rdf:type rdfs:Class .) und - Instanzierungen von Klassen durch
rdf:type(Bsp.: :Earth rdf:type :Planet .) zu machen; - Eigenschaften via
rdf:Propertyzu definieren und - sie durch die Festelllung von Domänen (
rdfs:domain) und Umfang (rdfs:range) zu limitieren; - hierarchische Beziehungen von Klassen (
rdfs:subClassOf) und EIgenschaften (rdfs:subPropertyOf) auszudrücken
Hinweise
- rdf:Property sollte nicht mit rdf:predicate verwechselt werden!
- Alles im RDF-Modell ist eine Resource (
rdfs:Resource) - Eine rdfs:class ist immer rekursiv (rdfs:Class a rdfs:Class)
- Eine Klasse ist eine Resource und eine Resource ist immer auch eine Klasse
- Klassen, die eine rdfs:Property sind, werden per Konvention klein geschrieben (Bsp.: rdfs:subClassOf)
Subset von RDFS und dessen Beziehungen:
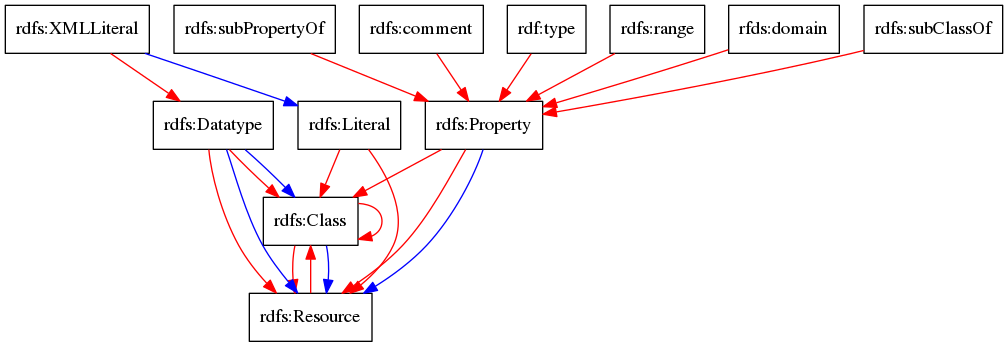 Blau: Instanz-Beziehung; Rot: subClass-Beziehung
Blau: Instanz-Beziehung; Rot: subClass-Beziehung
Weitere Eigenschaften:
- rdfs:seeAlso: Definiert die Beziehung einer Resource zu einer anderen, welche jene definiert
- rdfs:isDefinedBy: Untereigenschaft von rdfs:seeAlso, definiert die Beziehung zwischen einer Resource und ihrer Definition
- rdfs:comment: Kommentar
- rdfs:label: “Lesbarer” Name einer Resource
- rdfs:member: super-property of all the container membership properties (e.g. rdf:_1, …)
Normalerweise wird in einer RDFS-Serialisierung zuerst die Klassendefinitionen, dann die Eigenschaftsdefinitionen und schlussendlich die Instanzendefinitionen festgehalten.
03 - Logical Inference with RDFS #
- rdfs:domain definiert die Domäne, zu der eine bestimmte rdfs:Property gehören muss. D.h. also, ein Subjekt ist immer ein Typ der von der Eigenschaft definierten Domäne.
- rdfs:range definiert den Umfang, auf den sich eine bestimte rdfs:Property bezieht. D.h. also, ein Objekt ist immer ein Typ des von der Eigeschaft definierten Umfangs.
04 - How to query RDF(S)? SPARQL #
SPARQL (SPARQL Protocol and RDF Query Language) is
- a Query Language for RDF graph traversal (SPARQL Query Language Specification)
- a Protocol Layer to use SPARQL via http (SPARQL Protocol for RDF Specification)
- an XML Output Format Specification for SPARQL queries (SPARQL Query XML Results Format)
- W3C Standard
Hinweise zur SPARQL-Syntax:
- Präfix-Definitionen in SPARQL enden im Gegensatz zu RDF nicht mit einem Punkt!
- Bnodes sind “non selectable variables”, d.h., sie können nicht in einem SELECT-statement aufgeführt werden
FILTER contstraints:
- FILTER expressions contain operators and functions
- FILTER can not assign/create new values
05 - SPARQL is more than a Query Language #
- ASK (im Gegensatz zu SELECT) liefert ein Boolescher Wert, ob eine Anfrage Treffer hat oder nicht
- DESCRIBE liefert Informationen über eine Resource zurück
- CONSTRUCT erstellt ein neuer RDF graph gemäss einer Vorlage (Bsp.: (…)
CONSTRUCT { ?author <http://example.org/hasWritten> ?work . }(…))
06 - Complex queries with SPARQL #
Einige weitere Operatoren:
- FILTER REGEX (, , )
- OPTIONAL: Optionale Bedingung (für zusätzliche Ausgabe durch SELECT) Aussage wird mit {} umfasst
- UNION: Kombination zweier Graphen durch eine logische Disjunktion
- FILTER NOT EXISTS
- MINUS: Unterscheidet sich von NOT EXISTS dadurch, dass es den Graph Pattern verändert und somit die Position von MINUS für das Resultat ausschlaggebend ist
- Named Graphs (zusätzliche Graphen in demselben Endpoint) können mit dem Schlüsselwort GRAPH aufgerufen und mit FROM NAMED definiert werden
- SERVICE dient für föderierte Suchen
Drei-wertige Logik bei logischen Operationen: true, false, error
07 - More complex SPARQL queries #
- Agreggate Functions:
- SELECT COUNT() AS <neue_variable>
- SELECT COUNT(DISTINCT()) AS <neue_variable>
- GROUP BY: Gruppiert Resultat auf Basis einer bestimmten Variablen
- Mit HAVING können Aggregationen gefilter werden
08 - SPARQL Subqueries and Property Paths #
Property paths: Eine möglicher Weg durch einen RDF-Graph zwischen zwei Knoten. Sie können u.a. als Alternative zu Subqueries gesehen werden:
- Alternatives: Eine oder mehrere Möglichkeiten treffen zu (Bsp.:
{:book dc:title|rdfs:label ?displayString }) - Sequence (wo Länge des property path > 1): Definiert eine Abfolge von Eigenschaften (Bsp.:
{ ?x foaf:knows/foaf:knows/foaf:name ?name . }) - Inverse property paths: Richtung des Graphen drehen (Bsp.:
{?x foaf:mbox <mailto:alice@example> . <mailto:alice@example> ^foaf:mbox ?x . }) - Arbitrary length match: Arbiträre Länge der gleichen Eigenschaft suchen (Bsp.:
{?x foaf:mbox <mailto:alice@example> . ?x foaf:knows+/foaf:name ?name . }=> Es sind auch andere Regex-Operatoren möglich, bspw. *, {2} etc. - Negation: Alle Eigenschaften, die nicht der definierten Eigenschaft entsprechen (Bsp.:
{ ?x !(rdf:type|^rdf:type) ?y .})