Apache Flink #
- Incubating project at Apache since April 2014
- Top-level project since January 2015
Domains of streaming applications:
- Data analytics
- ETL
- Transactional applications (typically with different tiers for data processing and transactional data storage)
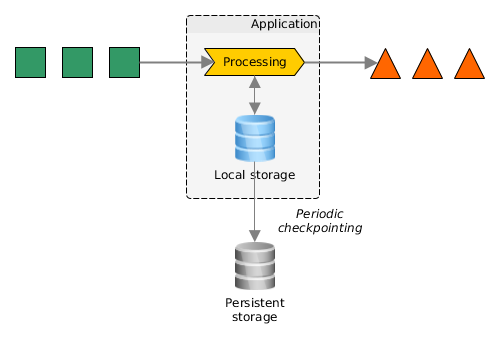
Application state is stored either locally in memory or in an embedded database.
Since Flink is a distributed system, local state needs to be protected against failures to avoid data loss in case of application or machine failure. Guaranteed by periodically writing a consistent checkpoint of application state to persistent storage.
Key concepts #
Dataflow program: Describes how data flows between operations; commonly represented as directed graphs Nodes in a dataflow program are called operators and represent computations; basic functional units of dataflow applications Data source: Operator without input port Data sink: Operator without output port Dataflow graph must have at least one data source and one data sink
Logical (dataflow) graph: Convey a high-level view of the computation logic. Nodes in a logical graph are called operators. An operator chain is a group of two or more consecutive operators without any repartitioning in between (e.g. no intermediary serialisation)
Physical (dataflow) graph / ExecutionGraph: Is the result of translating a logical graph for execution in a distributed runtime and specifies in detail how the program is executed; the nodes are now called (operator) tasks
Data parallelism: Tasks of the same operation execute on the data subsets in parallel
Task parallelism: Tasks from different operators perform computations on the same or different data in parallel (i.e. better utilization of the computer resources of a cluster)
Job parallelism: Tasks from different jobs are executed in parallel
Data exchange strategies (automatically chosen by the execution engine or manually set):
- Forward strategy: Sends data from a task to a receiving task. If both tasks are located on the same machine, network communication is avoided
- Broadcast strategy: Sends every data item to all parallel tasks of an operator. Fairly expensive because of data replication and network traffic
- Key-based strategy: Partitions data by a key attribute and guarantees that data items having the same key will be processed by the same task
- Random strategy: Uniformly distributes data items to tasks in order to evenly distribute the load across computing tasks
Data stream: A potentially unbounded sequence of events
Latency: Indicates how long it takes for an event to be processed Throughput: Processing capacity (how many events are processed in a unit of time?). Usually the goal is to ensure that the system can handle the maximum expected rate of events, otherwise backpressure happens
Window Operations #
- Window operations continuously create finite sets of events called buckets fom an unbounded event stream and let us perform computations on these finite sets.
- Window policies: When are new buckets created? Which events go to which buckets (usually based on data properties, on counts, or on time)? When do the contents of a bucket get evaluated (trigger condition)?
- Three types of windows:
- Tumbling windows: Nonoverlapping buckets of fixed size
- Sliding windows: Overlapping buckets of fixed size. Slide value defines the interval at which a new bucket is created, so slide value < fixed length (when defined, length and slide are provided)
- Session windows: Useful if the length of a window cannot be decided upon beforehand and rather depends on the actual data. Sessions are comprised of a series of events happening in adjacent time followed by a period of inactivity. A session gap value delimits the buckets.
- Usually windows are run in parallel. In parallel windows, each partition applies the window policies independently of other partitions
Time Semantics #
Advantages of processing time:
- Introduces lowest latency possible
- More suitable if a periodically report of results in real time is required
- Faithful representation of the stream itself (e.g. to count the number of events per second to detect outages)
Advantages of event time:
- Is deterministic
- Guarantees result correctness even in cases of out-of-order / delayed data
- Streams are replayable and historic data replayable as if events are happening in real time.
- Computation can be fast forwarded to the present so that the program catches up with the events happening now
Watermarks #
- Essentially a timestamp which indicates to an operator that no messages with event time prior to the watermark are to be expected anymore
- Delays are subtracted from the timestamp, which can be e.g. the current system time or the timestamp extracted from the message itself (better).
- So every event essentially says: “After me no more messages with a timestamp smaller than my timestamp minus x will arrive”. The operator than checks if this computed timestamp is bigger than a certain window boundary. If so, it closes the window.
- Tradeoff: Eager watermarks ensure low latency but provide lower confidence; “lazy” watermarks provide high confidence but also high latency
- Allowed lateness: Instead of always delaying the firing of a window, allowed lateness retriggers the firing of the window if a delayed event within the allowed timespan arrives. Of course the action should be idempotent to guarantee exactly-once semantics.
State and Consistency Models #
Challenges:
- State management: The system needs to efficiently manage the state and make sure it is protected from concurrent updates
- State partitioning: Parallelization gets complicated, since results depend on both the state and incoming events. Fortunately, in many cases, you can partition the state by a key and manage the state of each partition independently. For example, if you are processing a stream of measurements from a set of sensors, you can use a partitioned operator state to maintain state for each sensor independently.
- State recovery: The third and biggest challenge that comes with stateful operators is ensuring that state can be recovered and results will be correct even in the presence of failures.
Two types of state:
- Keyed State:
- Always relative to keys
- Can only be used in functions and operators on a
KeyedStream - Operator state that has been partitioned with exactly one state-partition per key
- Bound to a unique composite of <parallel-operator-instance, key>, or, since each key “belongs” to exactly one parallel instance of a keyed operator, to <operator, key>
- Key groups: Atomic unit by which Flink can redistribute Keyed State; no of keyed state = defined maximum parallelism. Thus during execution each parallel instance of a keyed operator works with the keys for one or more Key Groups
- Operator State (non-keyed state):
- Each operator state is bound to one parallel operator instance (i.e. a task). The state cannot be accessed from another task of the same or another operator.
- Example: Kafka Connector, where each parallel instance of the Kafka consumer maintains a map of topic partitions and offsets as its Operator State
Furthermore two forms of state for the two types of state:
- Managed State: Represented in data structures controlled by Flink runtime. Encoded by Flink’s runtime and written by it into the checkpoints
- Raw State: Kept by operators in their own data structures. Written as a raw bytes into the checkpoints by the operator.
Primitives used in Managed Keyed State:
ValueState<T>ListState<T>ReducingState<T>AggregatingState<IN, OUT>FoldingState<T, ACC>(deprecated)MapState<UK, UV>
To get a state handle, a respective StateDescriptor (ValueStateDescriptor etc.) has to be created. State is accessed using the RuntimeContext, so it is only possible in rich functions.
Primitives in Operator State:
- List state: Represents state as a list of entries
- Union list state: Represents state as a list of entries as well. But it differs from regular list state in how it is restored in the case of a failure or when an application is started from a savepoint.
- Broadcast state: Designed for the special case where the state of each task of an operator is identical. This property can be leveraged during checkpoints and when rescaling an operator.
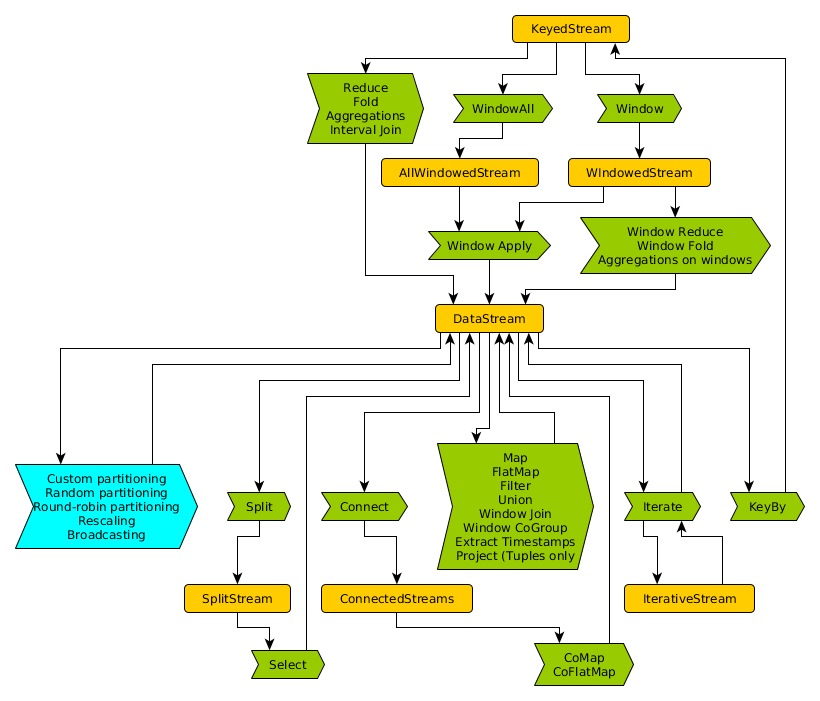
Streams API #
Operators #
Architecture of Flink #
Flink Cluster Components #
- JobManager:
- Master process, controls the execution of a single application
- Each application is controlled by a different JobManager
- Receives application (which consists of a JobGraph and a JAR file) and converts JobGraph into a physical dataflow graph called ExecutionGraph)
- Requests the necessary resources (TaskManager slots) to execute the tasks from the ResourceManager.
- Distributes the tasks of the ExecutionGraph to the TaskManagers
- Responsible for all actions that require a central coordination such as the coordination of checkpoints
- ResourceManager:
- Responsible for managing TaskManager slots by instructing TaskManagers with idle slots to offer them to the JobManager
- Can talk to the resource provider to start more containers with running TaskManager processes
- Terminates idle TaskManagers to free resources
- Multiple ResourceManagers for different environments and resource providers
- TaskManager:
- Worker processes
- Provides a certain number of slots which limits the number of tasks a TaskManager can execute
- During execution, TaskManagers exchange data with other involved TaskManagers
- Dispatcher:
- Runs across job executions and provides a REST interface to submit applications for execution
- Starts a JobManager once an application is submitted for execution and hand the application over
- Runs web dashboard
- Depending on how an application is submitted for execution, a dispatcher might not be required (applications are then delivered directly to the JobManager which executes them immediately)
Setup & Deployment #
Deployment Modes #
- Framework style: Application is packaged into a JAR and submitted by a client to a running service
- Library style: The application is bundled in an application-specific container image, such as a Docker image, which includes also the code to run a JobManager and a ResourceManager. Other containers provide TaskManagers, which connect to the ResourceManager inside the application container and register their slots. Typically such a setup is used on Kubernetes. For further instructions see here.
Neues Flink-Projekt aufsetzen (Scala) #
sbt new tillrohrmann/flink-project.g8
Docker #
Hinweise zur Beispielanwendung #
Damit die Beispielanwendung funktioniert, muss die Hostname-Auflösung auf dem Gastsystem korrekt funktionieren. S. für Arch Linux dazu https://wiki.archlinux.org/index.php/Hostname#Set_the_hostname.
Resources #
- How To Size Your Apache Flink Cluster: A Back-of-the-Envelope Calculation
- 4 Ways to Optimize Your Flink Applications
Problems #
GC #
- https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=53741525
- https://stackoverflow.com/questions/41845343/flink-cluster-execution-error-of-loss-of-taskmanager
- https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
- https://www.oracle.com/technetwork/articles/java/g1gc-1984535.html