Kafka Streams #
- Data processing / transformation library within Kafka
- Exactly once capabilities (>= version 0.11)
- One record at a time processing
- Supports event-time based windowing operations with late arrival of records
- Two APIs:
- High Level Kafka Streams DSL
- Low Level Processor API
- Allows developers define and connect custom processors as well as to interact with state stores
- Rarely used, for the most complex logic
- Leverages the Consumer and Producer API, therefore all the respective configurations are applicable
- Since the application is also a consumer, it will try to resume where it left off the last last time
- It is not recommended to write the result to an external system inside a Kafka Streams application. Use Kafka Streams to transform the data and then use Kafka Connect API to do the writing
Basic vocabulary #
- Stream: Unbounded sequence of immutable data records, that is fully ordered, can be replayed, and is fault tolerant
- Stream processor: Node in the processor topology. It transforms incoming streams, record by record, and may create a new stream from it
- Source processor: Special processor that takes its data directly from a Kafka topic. It has no predessors in a topology, and doesn’t transform the data
- Sink processor: Processor that does not have children. It sends the stream data directly to a Kafka topic.
- Topology: Graph of processors chained together by streams
Exactly Once Semantics #
- Exactly once isthe ability to guarantee that data processing on each message will happen only once, and that pushing the message back to Kafka will also happen effectively only once (Kafka will de-dup). So the guarantee does not extend to exactly once delivery.
- Guaranteed when both input and output system is Kafka, not for Kafka to any external systems
- Message transmission happens in four steps:
- Kafka Streams application receives message
- Kafka Streams application sends ouput back to Kafka
- Kafka Streams application receives ack
- Kafka Streams application commits offset
- Since Kafka guarantees at-least once semantics, a failure in step c. or d. triggers a retry. But how does Kafka then achieves exactly once?
- The producers are now idempotent (if the same message is sent twice or more due to retries, Kafka will make sure to only keep one copy of it).
- You can write multiple messages to different Kafka topics as part of one transaction (either all are written, or none is written). This is a new advanced API
- To enable exactly once semantics in Kafka Streams:
props.put(StreamsCofnig.PROCESSING_GUARANTEE_CONFIG, StreamConfig.EXACTLY_ONCE); - What’s the trade-off?
- Results are published in transactions, which might incure a small latency
- You fine tune that setting using
commit.interval.ms
KStream and KTables Duality #
- Stream as Table: A stream can be considered a changelog of a table, where each data record in the stream captures a state change of the table. Two ways to create:
groupByKey()+ aggregation (count,aggregate,reduce) or write back to Kafka and read as KTable - Table as Stream: A table can be considered a snapshot, at a point in time, of the latest value for each key in a stream (a stream’s data records are key-value pairs) (
toStream())
Internal Topics #
- Running a Kafka Streams may eventually create internal intermediary topics
- Two types:
- Repartitioning topics: in case you start transforming the key of your stream, a repartitioning will happen at some processor
- Changelog topics: in case you perform aggregations, Kafka Streams will save compacted data in these topics
- Internal topics:
- Are managed by Kafka Streams
- Are used by Kafka Streams to save / restore state and re-partition data
- Are prefixed by application.id parameter
- Never add to / delete them!
Application setup #
Basic dependencies:
org.apache.kafka:kafka-streamsorg.slf4j:slf4j-apiorg.slf4j:slf4j-log4j12
Important settings #
bootstrap.servers: Needed to connect to Kafka, comma-separated (required)application.id(required), used for:- Identical to consumer
group.id! - Default
client.idprefix - Prefix to internal changelog topics (see below)
- Identical to consumer
auto.offset.reset.config:earliest,latestdefault.[key|value].serde: For serialisation and deserialisation purposes
Log Compaction and Kafka Streams #
- Log Compaction can be a huge improvement in performance when dealing with KTables because eventually records get discarded
- This means less reads to get to the final state (less time to recover)
- Log Compaction has to be enabled by you on the topics that get created (source or sink topics)
Basic structure #
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.kstream.StreamsBuilder;
import org.apache.kafka.streams.processor.Topology;
// Use the builders to define the actual processing topology, e.g. to specify
// from which input topics to read, which stream operations (filter, map, etc.)
// should be called, and so on. We will cover this in detail in the subsequent
// sections of this Developer Guide.
StreamsBuilder builder = ...; // when using the DSL
Topology topology = builder.build();
//
// OR
//
Topology topology = ...; // when using the Processor API
// Use the configuration to tell your application where the Kafka cluster is,
// which Serializers/Deserializers to use by default, to specify security settings,
// and so on.
Properties props = ...;
KafkaStreams streams = new KafkaStreams(topology, props);
// Read from input topic (source). The types of key and value should be equivalent to the ones of the deserializers defined
KStreams<String, String> source = builder.stream("topic-name");
// Processors ...
// Send data to output topic
out.to(Serdes.String(), Serdes.Long(), "output-topic");
// Shutdown hook. Must be the last line of code
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
- A source can be one of
- a single topic,
- multiple topics in a comma-separated list,
- a regex that can match one or more topics
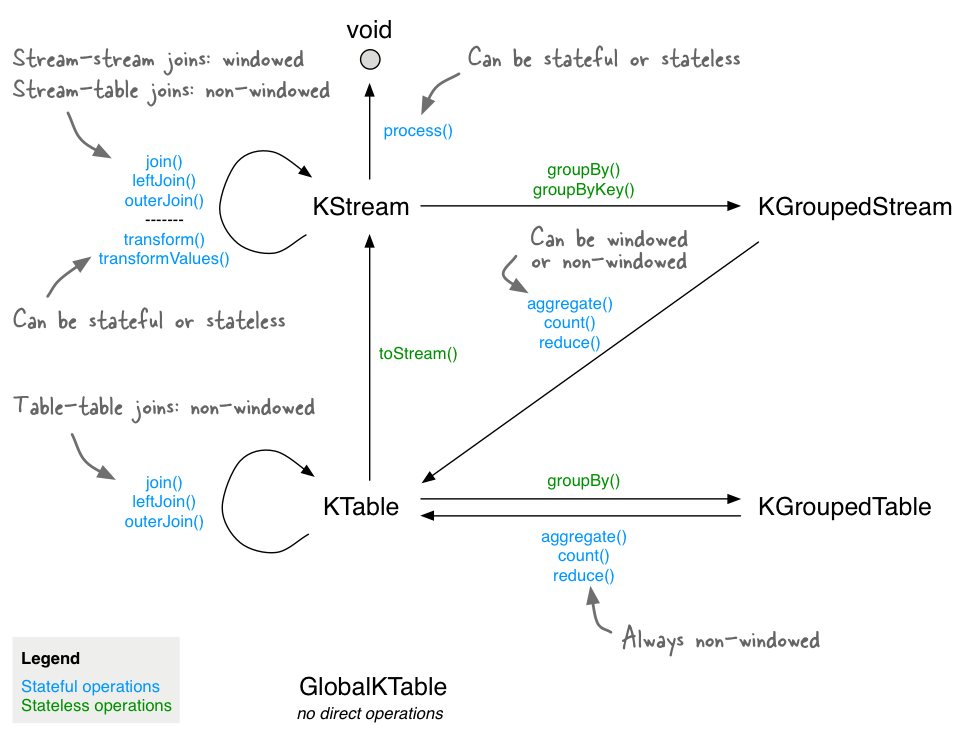
KStream and KTable Simple Operations #
Documentation: https://docs.confluent.io/current/streams/developer-guide.html#transform-a-stream
KStreams vs. KTables vs. GlobalKTables #
KStreams:
- Abstraction of a record stream, where each data record represents a self-contained datum in the unbounded data set
- All inserts
- Similar to a log (with log compaction disabled, since that would break the semantics)
- Use it…
- …when reading from a topic that’s not compacted
- …if new data is partial information / transactional
KTables:
- Abstraction of a changelog stream, where each data record represents an update
- All upserts on non
nullvalues - Deletes on
nullvalues - Similar to a table
- Parallel with log compacted topics
- Use it…
- ….when reading from a topi that’s log-compacted (aggregations)
- …if you need a structure that’s like a “database table”, where every update is self sufficient
GlobalKTables:
- Abstraction of a changelog stream (as it is the case with KTables)
- Aggregates from every partition (unlike KTables)
- Benefits of global tables:
- More convenient and/or efficient joins: Notably, global table allow you to prform star joins, they support “foreign-key” lookups (i.e., you can lookup data in the table not just by record key, but also by data in the record values), and they are more efficient when chaining multiple joins. Also, when joining against a global table, the input data does not need to be co-partitioned.
- Can be used to “broadcast” information to all the running instances of your application
- Downsides of global tables:
- Increased local storage consumption compared to the (partitioned) KTable because the entire topic is tracked.
- Increased network and Kafka broker load compared to the (partitioned) KTable because the entire topic is read.
Reading from Kafka #
-
You can read a topic as a
KStream, aKTable, or aGlobalKTableKStream<String, Long> wordCounts = builder.stream( Serdes.String(), Serdes.Long(), “word-counts-input-topic”);
KTable<String, Long> wordCounts = builder.table( Serdes.String(), Serdes.Long(), “word-counts-input-topic”);
GlobalKTable<String, Long> wordCounts = builder.globalTable( Serdes.String(), Serdes.Long(), “word-counts-input-topic”);
You must provide a name for the table (more precisely, for the internal state store that backs the table) in the case of KTable an GlobalKTable. This is required for supporting interactive queries against the table. When a name is not provided the table will not be queryable and an internal name will be provided for the state store.
Operations #
Stateless #
MapValues / Map #
- Takes one record and produces one record
MapValues:- Is only affecting values
- does not change keys
- does not trigger a repartition
- For KStreams and KTables
Map:- Affects both keys and values
- Triggers a re-partitions
- For KStreams only
Filter / FilterNot #
KStream->KStream/KTable->KTable- Takes one record and procudes zero or one record
Filter:- does not change keys / values
- does not trigger a repartition
- for KStreams and KTables
FilterNotis the inverseFilter
FlatMapValues / FlatMap #
KStream->KStream- Takes one record and produces zero, one or more record
FlatMapValues:- does not change keys
- does not trigger a repartition
FlatMap:- changes keys
- triggers a repartition
Branch #
-
KStream->KStream[] -
Branch (split) a KStream based on one or more predicates
-
Predicates are evaluated in order, if no matches, records are dropped
KStream<String, Long>[] branches = stream.branch( (key, value) -> value > 100, (key, value) -> value > 10, (key, value) -> value > 0 );
SelectKey #
- Assigns a new key to the record (from old key and value)
- marks the data for re-partitioning
- Best practice to isolate that transformation to know exactly where the partitioning happens
GroupBy #
-
KStream -> KGroupedStream, KTable -> KGroupedTable -
GroupBy allows you to perform more aggregations within a KTable
-
Trigger re-partition
KGroupedTable<String, Integer> groupedTable = table.groupBy( (key, value) -> KeyValue.pair(value, value.length()), Serdes.String(), Serdes.Integer());
Peek #
Peek(KStream->KStream)- Allows you to apply a side-effect operation to a
KStreamand get the sameKStreamas a result - Warning: It could be executed multiple times as it is side effect (in case of failure)
Further stateless operations:
Foreach(KStream->void,KTable->void)GroupByKey(KStream->KGroupedStream)Merge(KStream->KStream): Merge records of two streas into one larger streams without an ordering guaranteePrint(KStream->void): Prints the records toSystem.out(terminal operation)ToStream(KTable->KStream): Get the changelog stream of this table
Aggregations #
Count #
KGroupedStream->KTable,KGroupedTable->KTable- Counts the number of record by grouped key
- If used on
KGroupStream: Null keys or values are ignored - If used on
KGroupedTable:- Null keys are ignored
- Null values are treated as “delete” (= *tombstones *=
-1)
Aggregate #
KGroupedStream: You need an initializer (of any type), an adder, a Serde and a State Store name (name of your aggregation)KGroupedTable: You need an initializer (of any type), an adder, a subtractor, a Serde and a State Store name (name of your aggregation)
Reduce #
- Similar to
Aggregate, but the result type has to be the same as the input
Joins #
- Joining means taking a
KStreamor / andKTableand creating a newKStreamorKTablefrom it - 4 kind of joins:
| Join operands | Type | (INNER) JOIN | LEFT JOIN | OUTER JOIN |
|---|---|---|---|---|
| KStream-to-KStream | Windowed | Supported | Supported | Supported |
| KStream-to-KTable | Non-windowed | Supported | Supported | Supported |
| KStream-to-KTable | Non-windowed | Supported | Supported | Not supported |
| KStream-to-GlobalKTable | Non-windowed | Supported | Supported | Not supported |
| KTable-to-GlobalKTable | N/A | Not supported | Not supported | Not supported |
The first three joins can only happy if the data is co-partitioned:
- Same number of partitions on stream / on table => If not, shuffle (write back data to Kafka)
GlobalKTable:
- Table data lives on every Streams application instance
- Data doesn’t have to be co-partitioned
- If data is resonably small
Writing to Kafka #
- You can write any
KStreamorKTableback to Kafka - If you write a
KTableback to Kafka, think about creating a log compacted topic! to: Terminal operation - write the records to a topicthrough: write to a topic and get a stream / table from the topic
Streams marked for re-partition #
- As soon as an operation can possibly change the key, the stream will be marked for repartition:
MapFlatMapSelectKey
- So only use these APIs if you need to change the key, otherwise use their counterparts:
MapValuesFlatMapValues
- Repartitioning is done seamlessly behind the scenes but will incur a performance cost (read and write to Kafka)
Processor API #
Besides the Stream DSL, there is also the low-level Processor API. It can be used on its own or leveraged from the Stream DSL.
From the Stream DSL #
Main reasons:
- Customization: Implementing custom logic not available in the Stream DSL
- Flexibility where it is needed: For example only the Processor API allows querying the metadata of a record (topic, partition, offset etc.)
There are three ways to integrate the Processor API into a Stream DSL-based topology:
- process: Applies a
Processorto each record. Terminal operation! Essentially equivalent to adding theProcessorviaTopology#addProcessor()to the processor topology. - transform: Applies a
Transformerto each record. Each input record is transformed into zero, one, or more output records (similar to the statelessflatMap). TheTransformermust return null for zero output. You can modify the record’s key and value, including their types.
Marks the stream for data re-partitioning
Standalone #
Testing #
http://kafka.apache.org/21/documentation/streams/developer-guide/testing.html
- Tests the Topology object of Kafka Streams application
- Does not require to run Kafka in tests:
- Consumer Record Generator (Factory)
- Kafka Streams Application in the middle
- Producer Record Reader + Tests
Error catching #
-
To catch any unexpected exceptions, you can set an
java.lang.Thread.UncaughtExceptionHandlerbefore you start the application. This handler is called whenever a stream thread is terminated by an unexpected exception:streams.setUncaughtExceptionHandler((Thread thread, Throwable throwable) -> { // here you should examine the throwable/exception and perform an appropriate action! }